We present MagicLens: a series of image retrieval models.
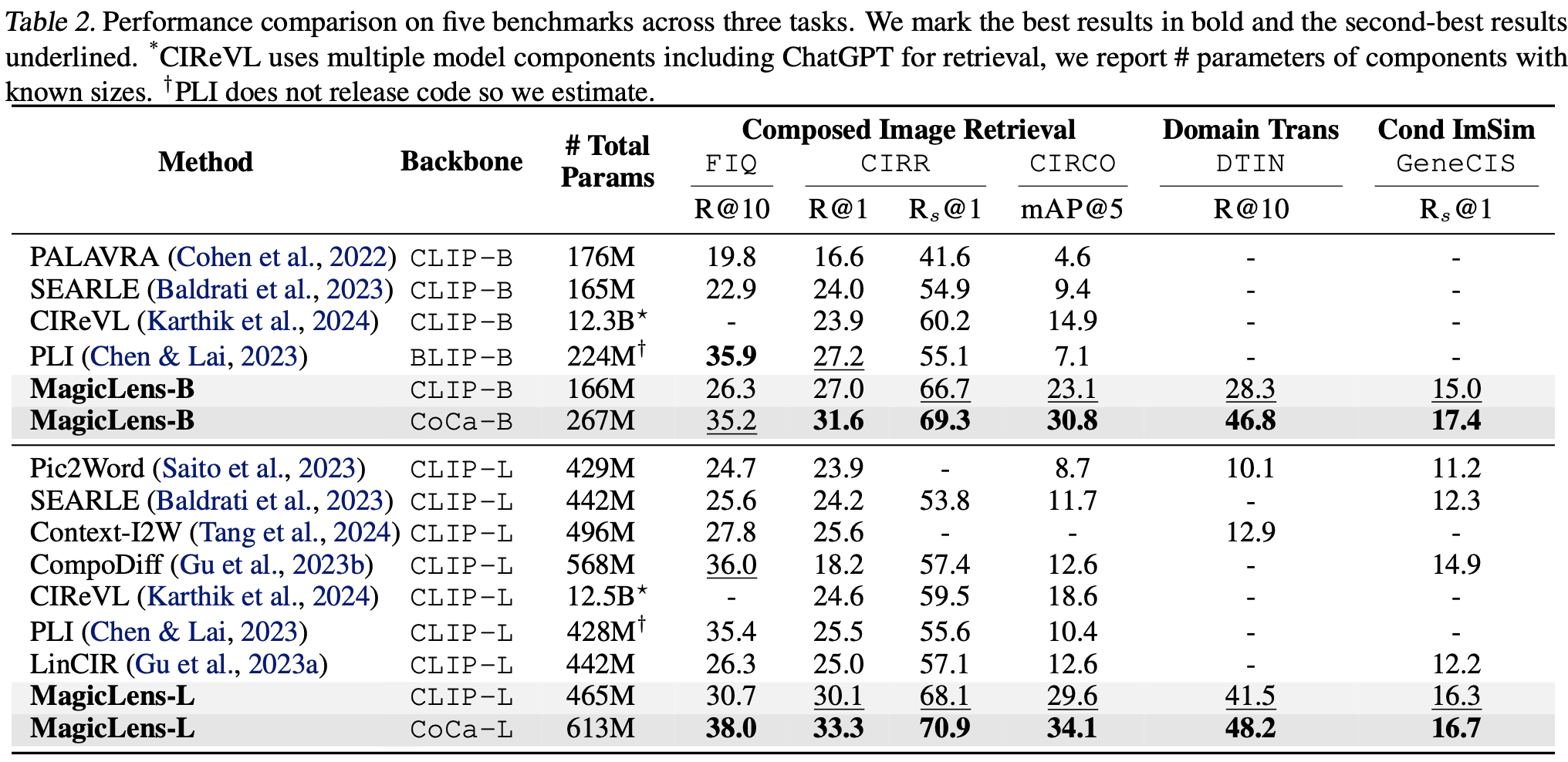
Trained on 36.7M (query image, instruction, target image) triplets with rich semantic relations mined from the web, a single MagicLens model can achieve comparable or better results on 10 benchmarks of various multimodality-to-image, image-to-image, and text-to-image retrieval tasks than prior state-of-the-art (SOTA) methods.
Also, MagicLens can satisfy diverse search intents expressed by open-ended instructions.
🔥Code and Models are available now!🔥
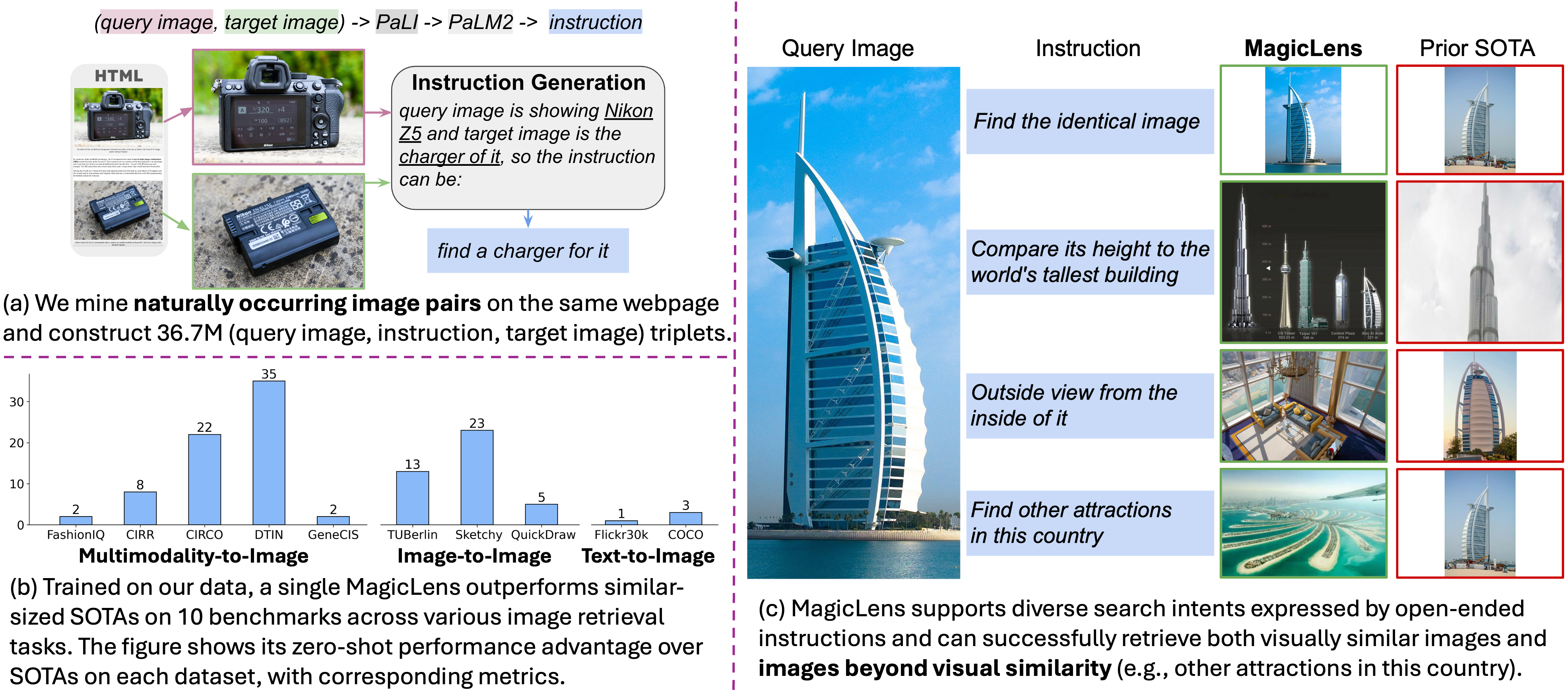
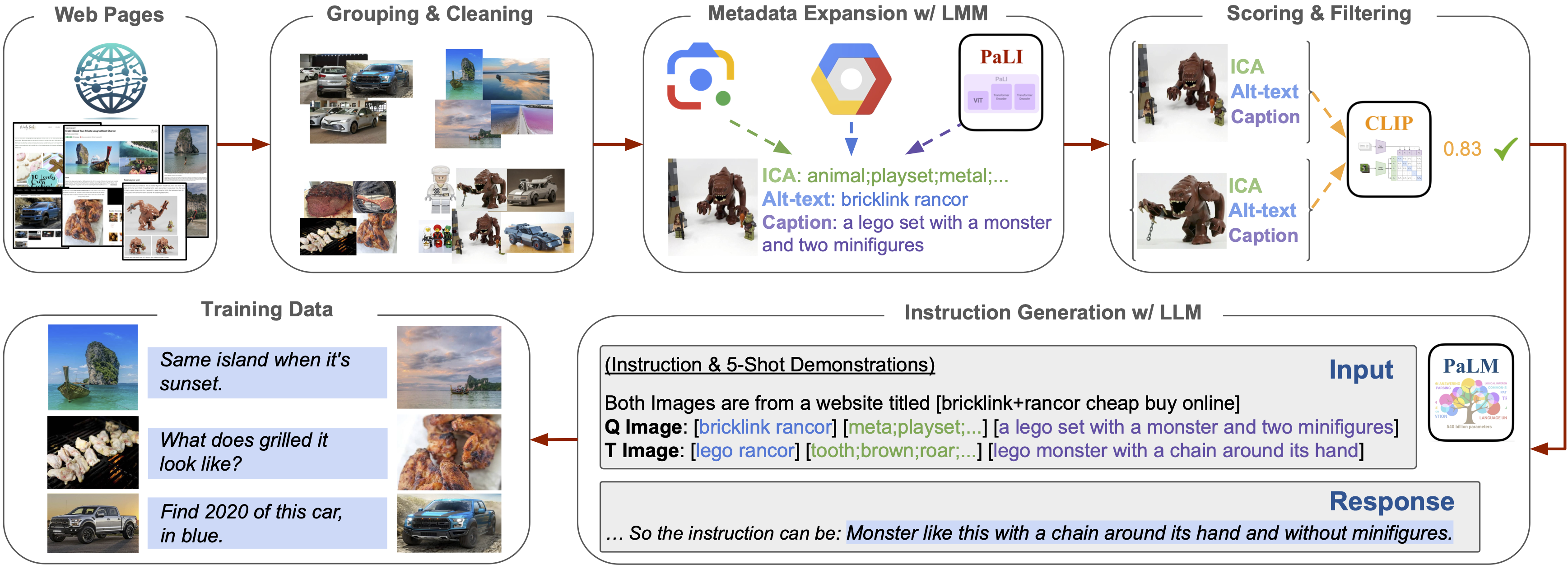
We mine naturally occuring image pairs from the same webpages, which implicitly cover diverse image relations. We utlize large multimodal models and large language models to construct 36.7M high quality triplets (query image, text instruction, target image) for model training.
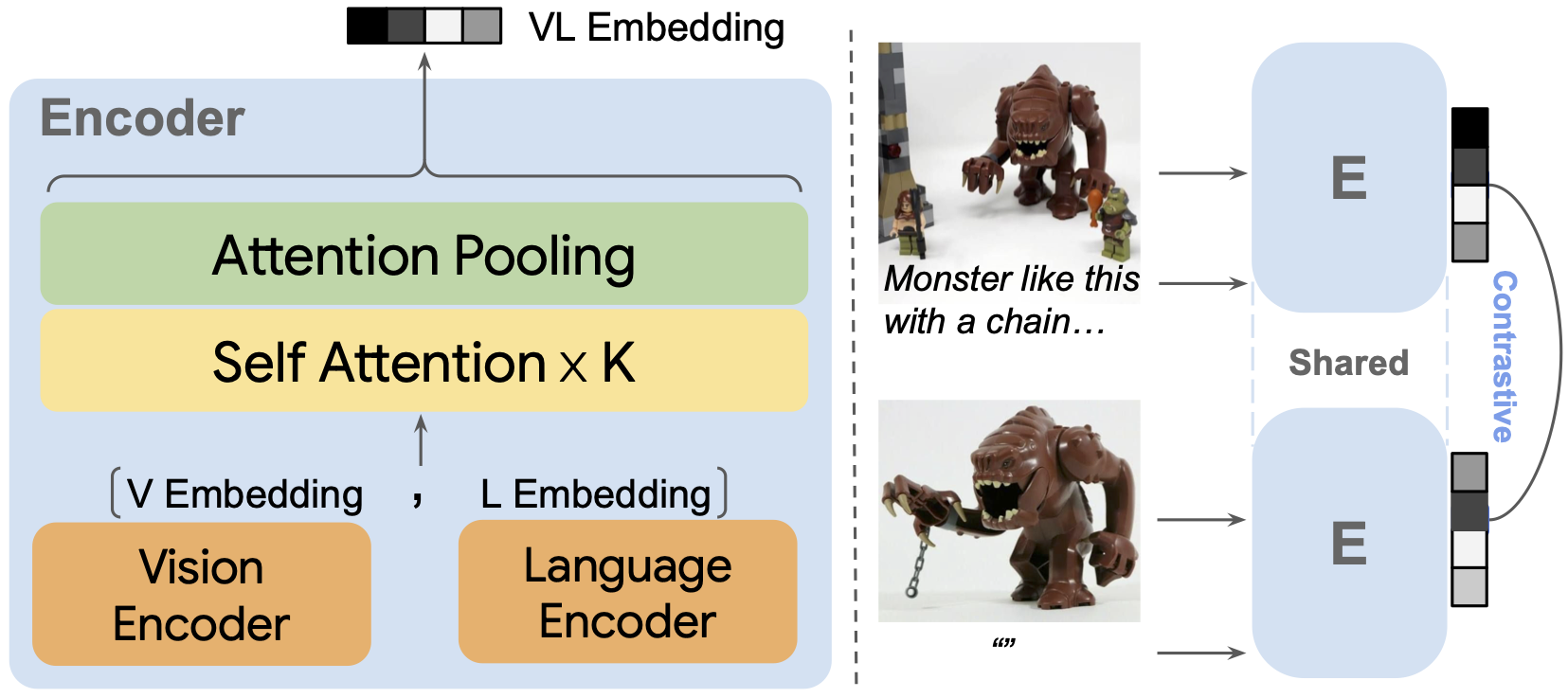
MagicLens is built upon single-modality encoders initialized from CLIP or CoCa and trained with simple contrastive loss. With a dual-encoder architecture, MagicLens can take both image and text inputs to deliver a VL embedding, thus enabling multimodal-to-image and image-to-image retrieval. Also, the bottom single-modality encoders can be re-used for text-to-image retrieval, with non-trivial performance gains.


@inproceedings{Zhang2024MagicLens,
title={MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions},
author={Zhang, Kai and Luan, Yi and Hu, Hexiang and Lee, Kenton and Qiao, Siyuan and Chen, Wenhu and Su, Yu and Chang, Ming-Wei},
booktitle={The Forty-first International Conference on Machine Learning (ICML)},
year={2024},
pages={to appear}
}